

Synthetische Daten – Lösung für Datenschutz und KI-Training?
Synthetische Daten revolutionieren die Art und Weise, wie wir mit Datenschutz und KI-Training umgehen.
Du fragst dich vielleicht, was genau Synthetic Data sind und welche Vorteile sie bieten?
Wir bei Newroom Media haben uns intensiv mit diesem Thema beschäftigt und möchten dir einen umfassenden Überblick geben.
Was sind synthetische Daten?
Synthetische Daten revolutionieren die Art und Weise, wie wir mit Informationen umgehen. Diese künstlich erzeugten Datensätze ahmen reale Daten in Struktur und statistischen Eigenschaften nach, ohne dabei sensible Informationen zu gefährden.
Definition und Unterschiede zu realen Daten
Im Gegensatz zu echten Daten stammen synthetische Daten nicht aus realen Quellen, sondern werden künstlich generiert. Trotzdem spiegeln sie die statistischen Muster und Beziehungen echter Daten wider. Ein entscheidender Vorteil liegt in ihrer DSGVO-Konformität, da sie keine persönlichen Informationen enthalten.
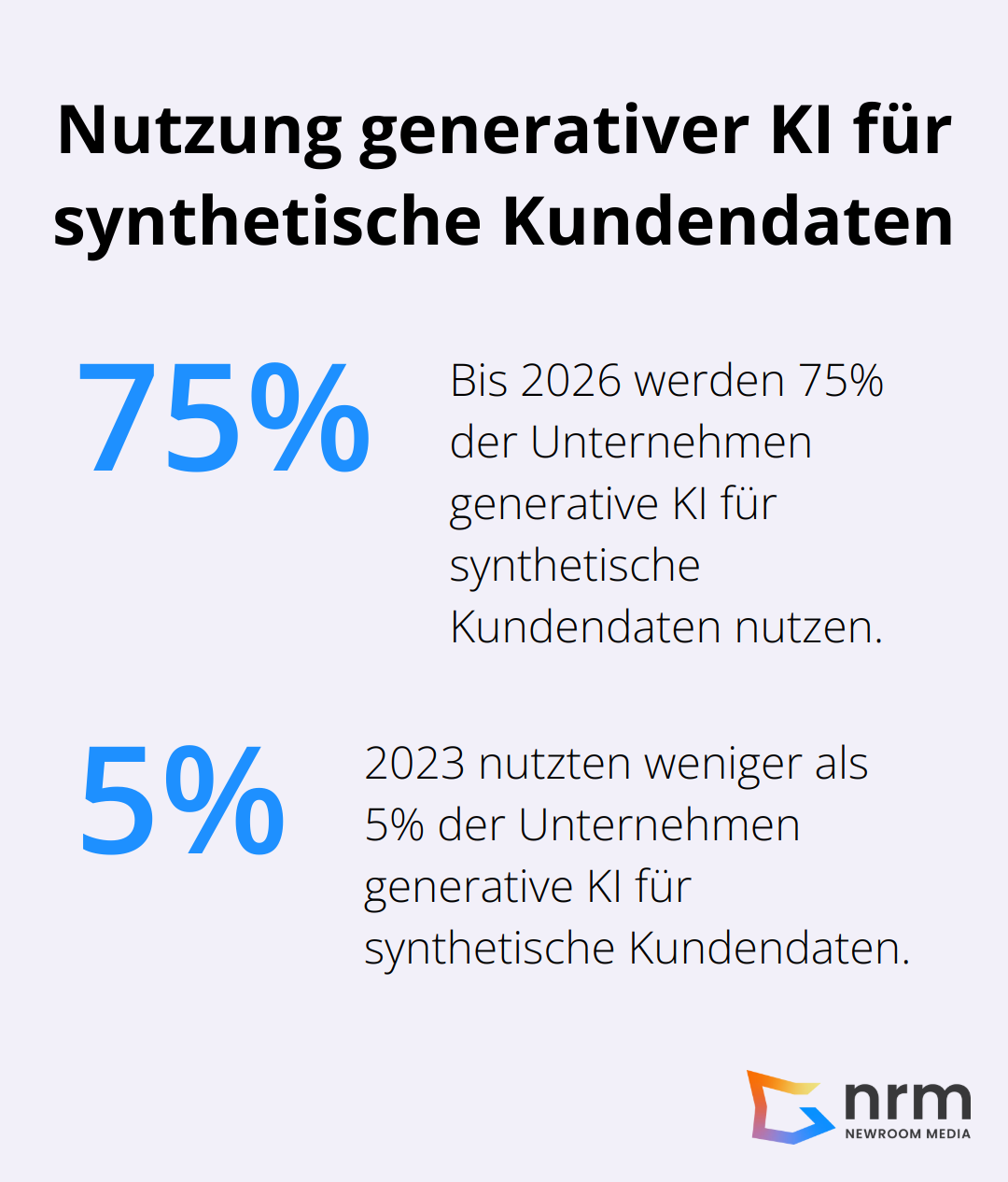
Gartner prognostiziert, dass bis 2026 75% der Unternehmen generative KI zur Erstellung synthetischer Kundendaten nutzen werden, während es 2023 noch weniger als 5% waren. Diese Prognose unterstreicht das enorme Potenzial dieser innovativen Technologie.
Erzeugungsmethoden für synthetische Daten
Die Generierung synthetischer Daten erfolgt durch verschiedene fortschrittliche Techniken:
Generative Adversarial Networks (GANs) erzeugen realistische Bilder und Daten. Sie finden häufig Anwendung bei der Generierung synthetischer Bilder und haben die Fähigkeit, täuschend echte Resultate zu liefern.
Variational Autoencoders (VAEs) eignen sich besonders gut zur Erzeugung von Datenvariationen. Diese Technik hilft, die Vielfalt in Datensätzen zu erhöhen und somit die Qualität des KI-Trainings zu verbessern.
Die regelbasierte Generierung nutzt bekannte Beziehungen und domänenspezifisches Wissen, um realistische Daten zu erzeugen. Diese Methode gewährleistet, dass die generierten Daten den spezifischen Anforderungen des jeweiligen Anwendungsbereichs entsprechen.
Vorteile synthetischer Daten
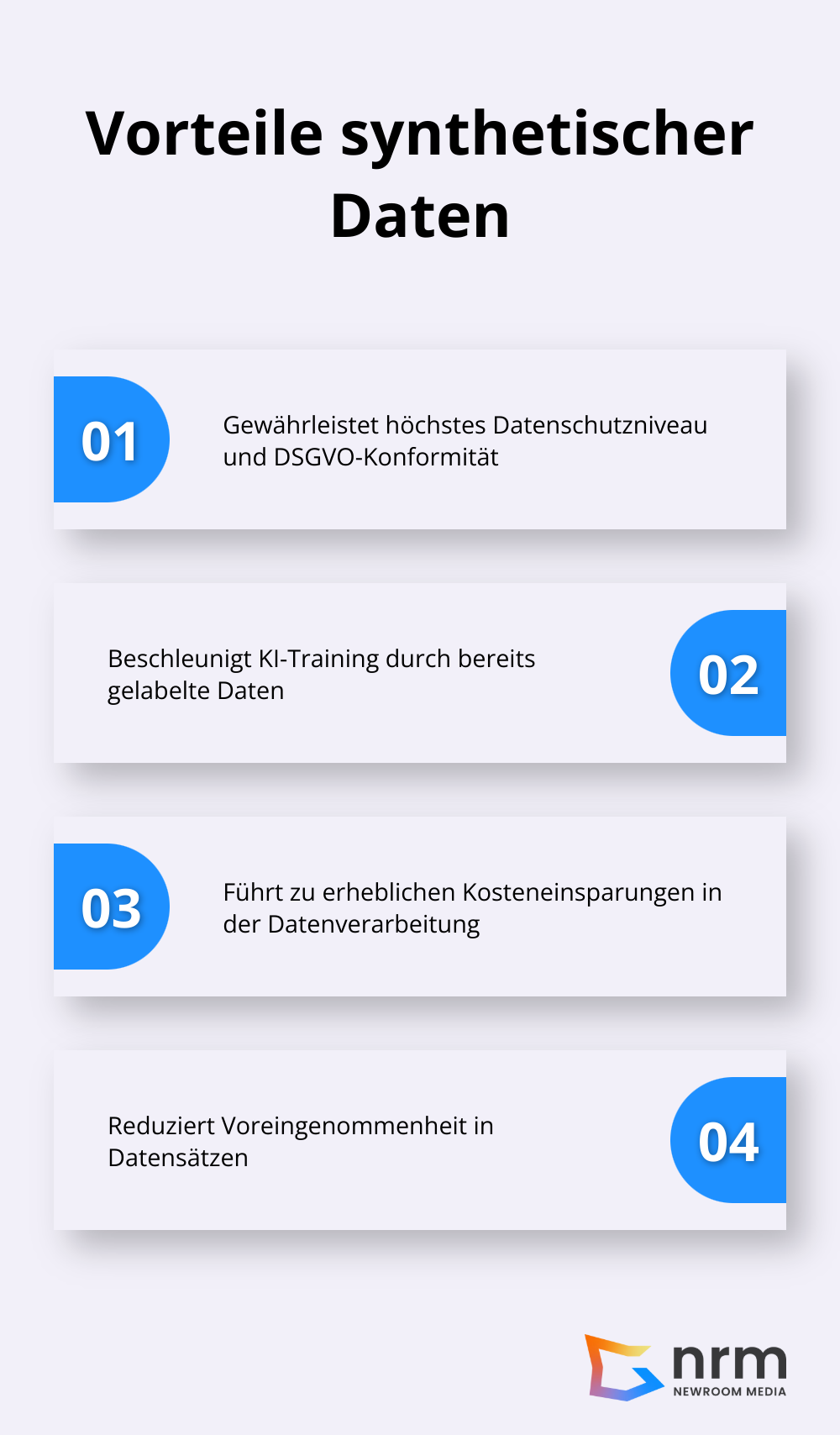
Synthetische Daten bieten beeindruckende Vorteile für das KI-Training. Sie ermöglichen eine Kosteneinsparung bei der Datengenerierung für KI-Modelle.
Ein weiterer Pluspunkt: Synthetische Daten sind bereits gelabelt. Das eliminiert den zeitaufwändigen Prozess des manuellen Labelns und beschleunigt die Entwicklung von KI-Modellen erheblich.
Darüber hinaus können synthetische Daten helfen, Datenlücken in unterrepräsentierten Gruppen zu schließen. Dies fördert die Vielfalt in Datensätzen und trägt zu faireren und ausgewogeneren KI-Systemen bei.
Die Verwendung synthetischer Daten eröffnet neue Möglichkeiten für Unternehmen, innovative KI-Lösungen zu entwickeln, ohne dabei sensible Daten zu gefährden. Diese Technologie bietet eine praktische Lösung für Datenschutzprobleme und verbessert gleichzeitig die Qualität des KI-Trainings.
Im nächsten Abschnitt werden wir uns genauer mit den Vorteilen synthetischer Daten befassen und untersuchen, wie sie Datenschutz, KI-Training und Kosteneffizienz positiv beeinflussen.
Wie revolutionieren synthetische Daten die Geschäftswelt?
Synthetische Daten verändern die Art und Weise, wie Unternehmen mit Daten umgehen, grundlegend. Sie bieten zahlreiche Vorteile, die sowohl den Datenschutz als auch die Effizienz von KI-Systemen verbessern.
Datenschutz auf höchstem Niveau
Synthetische Daten tragen maßgeblich zum Datenschutz bei. KI im Datenschutz bietet viele Vorteile, wie eine höhere Effizienz und Genauigkeit bei der Erkennung und Verarbeitung von Datenschutzrisiken. Da diese Daten künstlich erzeugt werden, enthalten sie keine persönlichen Informationen realer Personen. Das macht sie zu 100% DSGVO-konform und bietet eine sichere Alternative zu echten Daten. Unternehmen können so innovative KI-Lösungen entwickeln, ohne Gefahr zu laufen, sensible Kundendaten zu kompromittieren. Die Einhaltung strenger Datenschutzrichtlinien (wie GDPR und HIPAA) wird durch den Einsatz synthetischer Daten erheblich erleichtet.
Beschleunigung des KI-Trainings
Der Einsatz synthetischer Daten beschleunigt das KI-Training deutlich. Sie sind bereits gelabelt, was den zeitaufwändigen Prozess des manuellen Labelns überflüssig macht. Dadurch kann die Produktentwicklung um bis zu 70% schneller voranschreiten. Zudem lassen sich mit synthetischen Daten auch seltene Szenarien und Edge Cases simulieren, was die Robustheit von KI-Modellen erheblich verbessert. Diese Flexibilität ermöglicht es Unternehmen, schnell auf Marktveränderungen zu reagieren und neue Szenarien zu testen, ohne auf die Verfügbarkeit realer Daten warten zu müssen.
Kosteneffizienz als Game Changer
Synthetische Daten führen zu erheblichen Kosteneinsparungen. KI im Finanzwesen wird bis 2030 weltweit Einsparungen und Einnahmen in Höhe von über 1 Billion US-Dollar generieren. Diese beeindruckenden Zahlen verdeutlichen, warum immer mehr Unternehmen auf synthetische Daten setzen.
Reduzierung von Bias in Datensätzen
Ein oft übersehener Vorteil synthetischer Daten ist ihre Fähigkeit, Voreingenommenheit in Datensätzen zu reduzieren. Durch die gezielte Generierung von Daten können Unternehmen unterrepräsentierte Gruppen in ihren Datensätzen ausgleichen. Dies führt zu faireren und ausgewogeneren KI-Systemen, die eine breitere Palette von Szenarien und Nutzern abdecken.
Verbesserte Testabdeckung
Synthetische Daten ermöglichen eine umfassendere Testabdeckung. Unternehmen können eine Vielzahl von Szenarien simulieren, einschließlich seltener oder schwer zu reproduzierender Fälle. Dies führt zu robusteren und zuverlässigeren KI-Modellen, die besser auf reale Situationen vorbereitet sind.
Die Vorteile synthetischer Daten sind vielfältig und weitreichend. Sie verbessern nicht nur den Datenschutz und die Effizienz von KI-Systemen, sondern eröffnen auch neue Möglichkeiten für Innovation und Wettbewerbsfähigkeit. Trotz dieser beeindruckenden Vorteile gibt es jedoch auch Herausforderungen und Grenzen bei der Verwendung synthetischer Daten, die wir im nächsten Abschnitt genauer betrachten werden.
Wo liegen die Grenzen synthetischer Daten?
Synthetische Daten revolutionieren zwar die Datenlandschaft, stoßen aber auch an Grenzen. Trotz ihrer Vorteile müssen Unternehmen einige Herausforderungen meistern, um das volle Potenzial dieser innovativen Technologie auszuschöpfen.
Qualität und Realitätsnähe
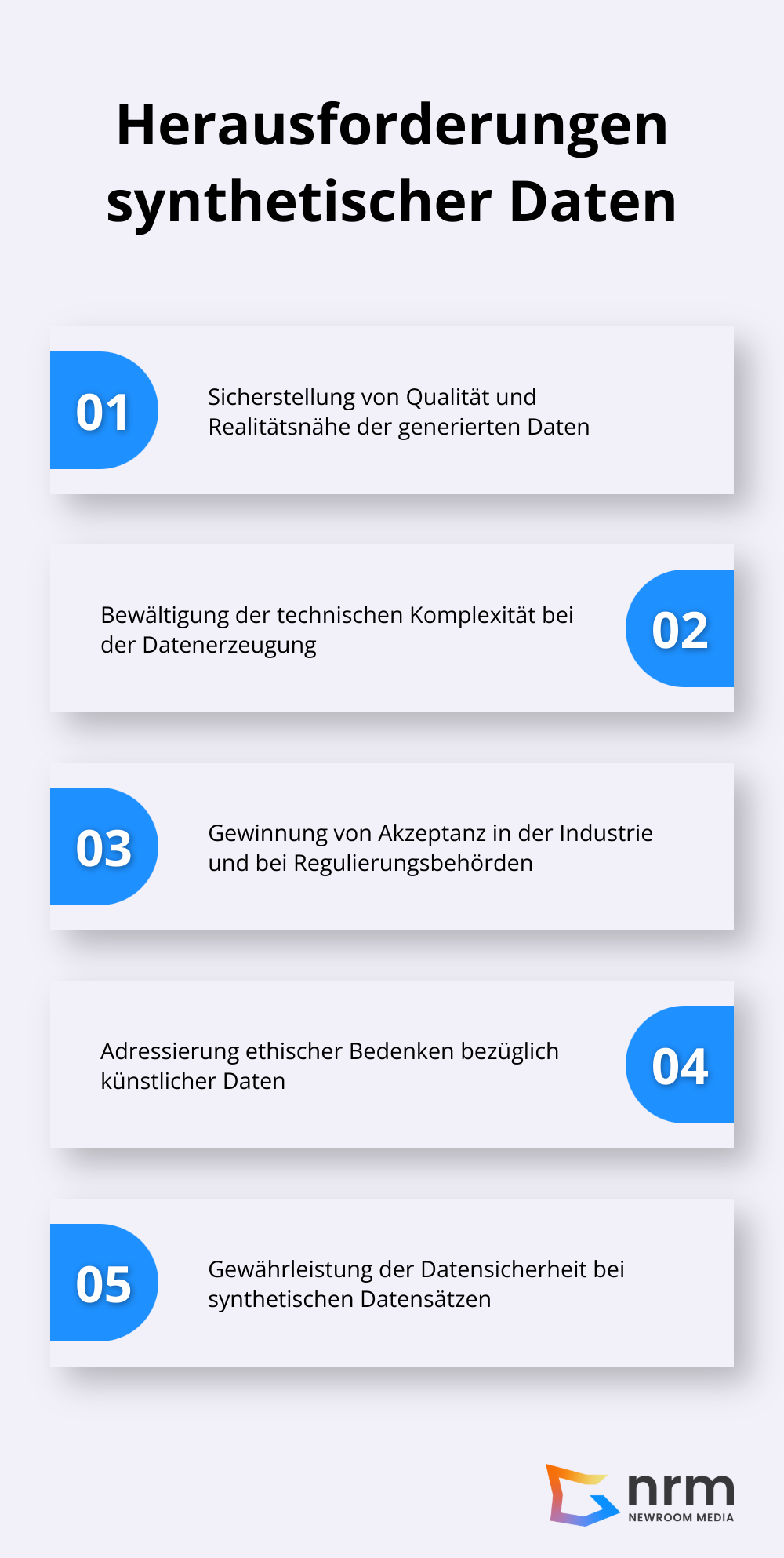
Die Qualität synthetischer Daten stellt eine zentrale Herausforderung dar. Trotz ihrer Vorteile bringen synthetische Daten auch Herausforderungen mit sich. Der Generierungsprozess kann komplex sein, da Data Scientists fortgeschrittene Techniken anwenden müssen, um realitätsnahe Daten zu erzeugen.
Unternehmen setzen auf rigorose Validierungsprozesse, um die Qualität zu gewährleisten. Sie vergleichen synthetische Daten mit realen Datensätzen (oft durch komplexe statistische Methoden). Dieser Prozess erfordert Zeit und Ressourcen, was die Effizienzvorteile synthetischer Daten teilweise aufhebt.
Technische Komplexität
Die Erzeugung hochwertiger synthetischer Daten verlangt fortgeschrittene technische Expertise und leistungsfähige Computersysteme. Kleinere Unternehmen stehen oft vor der Herausforderung, die notwendigen Ressourcen und das Know-how aufzubringen. Zwar vereinfachen Tools wie Synthetic Data Vault (SDV) den Prozess, erfordern aber dennoch technisches Verständnis.
Experten empfehlen, mit kleinen Pilotprojekten zu beginnen und die Komplexität schrittweise zu erhöhen. Dies ermöglicht es Unternehmen, Erfahrungen zu sammeln und ihre Fähigkeiten in der Generierung synthetischer Daten kontinuierlich zu verbessern.
Akzeptanz und Regulierung
Die Akzeptanz synthetischer Daten in der Industrie und bei Regulierungsbehörden stellt eine weitere Hürde dar. Trotz ihrer DSGVO-Konformität bestehen in einigen Branchen Vorbehalte gegenüber ihrer Verwendung, insbesondere in hochregulierten Sektoren wie dem Gesundheitswesen oder Finanzwesen.
Um diese Bedenken zu adressieren, arbeiten Unternehmen eng mit Regulierungsbehörden zusammen. Sie demonstrieren die Sicherheit und Zuverlässigkeit synthetischer Daten durch transparente Prozesse und umfassende Dokumentation. In einigen Fällen verfolgen sie hybride Ansätze, bei denen synthetische Daten mit anonymisierten Daten kombiniert werden, um die Akzeptanz zu erhöhen.
Ethische Bedenken
Die Verwendung synthetischer Daten wirft auch ethische Fragen auf. Kritiker argumentieren, dass die Erzeugung künstlicher Daten zu einer Verzerrung der Realität führen könnte. Dies gilt besonders in Bereichen wie der Sozialforschung oder der Kriminologie, wo synthetische Daten möglicherweise nicht die volle Komplexität menschlichen Verhaltens abbilden.
Unternehmen müssen sicherstellen, dass ihre synthetischen Datensätze keine unbeabsichtigten Vorurteile oder Diskriminierungen verstärken. Dies erfordert sorgfältige Überprüfungen und ethische Richtlinien für die Datengenerierung und -nutzung.
Datensicherheit
Obwohl synthetische Daten als datenschutzfreundlich gelten, bergen sie auch neue Sicherheitsrisiken. Angreifer könnten versuchen, die Algorithmen zur Datengenerierung zu manipulieren oder Rückschlüsse auf die ursprünglichen Daten zu ziehen. Unternehmen müssen robuste Sicherheitsmaßnahmen implementieren, um die Integrität ihrer synthetischen Datensätze zu schützen.
Die Entwicklung sicherer Methoden zur Erzeugung und Speicherung synthetischer Daten bleibt eine wichtige Forschungsaufgabe. Nur so lässt sich das Vertrauen in diese Technologie langfristig sichern.
Abschließende Gedanken
Synthetische Daten revolutionieren die Art und Weise, wie Unternehmen mit Informationen umgehen. Sie bieten eine DSGVO-konforme Lösung für Datenschutzherausforderungen und verbessern gleichzeitig die Qualität des KI-Trainings. Durch die Nutzung von Synthetic Data können Unternehmen Kosten sparen und ihre Modellgenauigkeit steigern, ohne sensible Daten zu gefährden. Diese innovative Technologie eröffnet neue Möglichkeiten für die Entwicklung fortschrittlicher KI-Lösungen in verschiedenen Branchen.
Trotz ihrer Vorteile stehen Unternehmen bei der Implementierung synthetischer Daten vor technischen und ethischen Herausforderungen. Die Erzeugung hochwertiger künstlicher Datensätze erfordert Expertise und leistungsfähige Systeme. Zudem müssen Unternehmen sicherstellen, dass ihre synthetischen Daten die Realität genau abbilden und keine unbeabsichtigten Verzerrungen enthalten. Die kontinuierliche Weiterentwicklung der Technologie verspricht jedoch, diese Hürden zu überwinden und den Einsatzbereich synthetischer Daten weiter auszudehnen.
Für Unternehmen, die ihre digitale Transformation vorantreiben möchten, bieten synthetische Daten enorme Chancen. Newroom Media unterstützt Sie dabei, das Potenzial dieser Zukunftstechnologie für Ihr Unternehmen zu erschließen. Mit maßgeschneiderten Lösungen und Erfahrungen von führenden Unternehmen helfen wir Ihnen, den digitalen Wandel optimal zu nutzen und Ihre Mitarbeiter für die Herausforderungen der Zukunft zu rüsten.